
Realize buscas textuais instantâneas com tolerância a erros de digitação utilizando CQRS e Meilisearch
No desenvolvimento de software, é extremamente comum iniciarmos sistemas utilizando bancos de dados relacionais tradicionais, como MySQL ou PostgreSQL, para gerenciar todas as operações da aplicação.
Quando surge a necessidade de criar uma barra de pesquisa, a reação instintiva da maioria dos desenvolvedores, acreidto eu, é recorrer à cláusula SQL:
SELECT * FROM products WHERE name LIKE '%termo%';No ambiente de desenvolvimento — ou com poucos milhares de registros — essa abordagem funciona de forma aceitável.
No entanto, à medida que o volume de dados cresce para centenas de milhares de linhas e o tráfego de usuários simultâneos aumenta, essa simples linha de código se transforma em uma das maiores armadilhas de performance de uma infraestrutura.
1. Por que o banco relacional “chora”?
Para entender o gargalo, precisamos olhar para como os bancos relacionais organizam seus índices.
Motores como o InnoDB (MySQL) utilizam uma estrutura chamada Árvore B+ (B+ Tree) para indexação.
Essa estrutura é otimizada para:
- Buscas exatas
WHERE id = 42- Ordenações
ORDER BY created_at- Consultas por intervalo
WHERE price BETWEEN 100 AND 500Porém… 😰
1.1 O Problema com %termo%
Quando realizamos uma busca com caractere coringa (“wildcards”) no início:
WHERE name LIKE '%matrix%'quebramos completamente a lógica de navegação da Árvore B+.
O banco não consegue prever quais caracteres iniciam o texto, então ele se torna incapaz de navegar pelo índice.
Mas, como assim? 🤔
a) Exemplo prático de Árvore B+ no mundo real
Bom, vamos fazer um paralelo com o mundo real.
Imagine uma biblioteca gigantesca 📚, os livros ficam organizados alfabeticamente pelo título nas prateleiras nos corredores.
Existe uma espécie de “mapa” dizendo:
- livros que começam com A → corredor 1
- livros que começam com B → corredor 2
- …
- livros que começam com M → corredor 13
e assim por diante.
Essa organização é o equivalente da Árvore B+.
Agora veja a diferença:
WHERE name LIKE 'matrix%'Aqui o banco sabe que o texto começa com “matrix”.
É como pedir:
“Quero livros cujo título começa com Matrix.”
O bibliotecário consegue:
- Ir direto para a seção M
- Encontrar o primeiro “Matrix”
- Ler sequencialmente dali em diante
Mas ao usar %matrix% a única alternativa restante é realizar um:
b) Full Table Scan
Ou seja, o banco precisa:
- Ler cada registro da tabela
- Carregar para memória
- Verificar manualmente se contém o termo pesquisado
Isso acarreta em:
- muitas leituras de disco
- mais uso de memória
- mais CPU
- mais tempo de resposta
2. Complexidade Algorítmica
Direto ao ponto, representa um crescimento linear, onde o trabalho aumenta proporcionalmente à quantidade de dados, como em uma busca que precisa verificar item por item até encontrar o resultado; já representa um crescimento logarítmico, onde o algoritmo reduz drasticamente o espaço de busca a cada etapa, como acontece em uma busca binária ou em índices baseados em Árvore B+, permitindo encontrar dados em poucas operações mesmo com milhões de registros. Se quiser se aprofundar nisso, pesquiso por Big O Notation.
Com índices normais:
ou até próximo de constante.
Com %termo%:
Isso significa que o custo cresce linearmente com a quantidade de registros.
Se tivermos:
- 500 mil registros
- 50 usuários simultâneos
- buscas constantes
o servidor sofrerá:
- explosão de I/O de disco
- saturação de CPU
- lentidão generalizada
- risco real de timeout e indisponibilidade
3. Outro problema: Busca rígida
Bancos relacionais exigem correspondência literal.
Se o usuário digitar:
matrxao invés de:
matrixo retorno será:
0 resultadosIsso gera frustração imediata.
4. A Solução arquitetural: CQRS
CQRS significa:
Command Query Responsibility Segregation
A ideia é separar:
- Command → escrita
- Query → leitura
4.1 Arquitetura
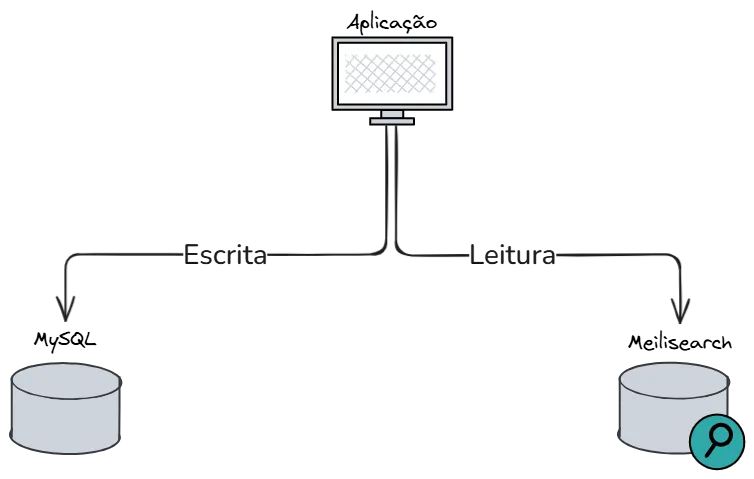
5. Lado de Escrita (Commands)
O MySQL continua sendo o banco transacional principal sendo responsável por:
- integridade referencial
- transações ACID
- consistência forte
- persistência oficial dos dados
Exemplo:
INSERT INTO products (...)
UPDATE orders SET status = 'paid'6. Lado de Leitura (Queries)
As buscas textuais pesadas são delegadas a motores especializados como:
- Meilisearch
- Elasticsearch
- Typesense
Esses motores mantêm uma cópia otimizada para pesquisa textual.
Exemplo:
GET /search?q=matrixBenefício Imediato
Ao remover buscas textuais do MySQL:
✅ O banco relacional fica livre para transações críticas
✅ Menor contenção de recursos
✅ Escalabilidade horizontal
✅ Redução drástica de gargalos
O sistema deixa de correr risco de cair porque muitos usuários estão usando a barra de busca ao mesmo tempo.
Por Que o Meilisearch é Tão Rápido?
O Meilisearch utiliza Índice Invertido.
Funciona como o índice remissivo de um livro:
Ao invés de ler o livro inteiro procurando uma palavra, você consulta o índice e descobre exatamente onde ela está.
Exemplo Conceitual
Ao indexar:
"Matrix Reloaded"
"Matrix Revolutions"
"John Wick"O índice invertido vira algo próximo disso:
{
"matrix": [1, 2],
"reloaded": [1],
"revolutions": [2],
"john": [3],
"wick": [3]
}Buscar "matrix" é praticamente instantâneo.
Performance
Enquanto uma busca SQL pesada pode levar:
- 100ms
- 300ms
- 500ms
No Meilisearch normalmente temos:
- < 2ms
Mesmo com milhões de documentos.
Recursos Nativos de UX
Tolerância a Erros
Se o usuário digitar:
matrxo sistema entende:
matrixIsso é possível usando distância de edição
(baseada em Levenshtein).
Search-as-you-type
Resultados aparecem a cada tecla:
m
ma
mat
matr
matri
matrixExperiência instantânea.
Ranking de Relevância
Você pode priorizar campos.
Exemplo:
Dar mais peso para:
- título
do que para:
- descrição
Exemplo:
{
"rankingRules": [
"title",
"description"
]
}Consistência Eventual
Ao adotar CQRS, aceitamos que os dados existem em dois lugares:
- MySQL
- Meilisearch
Isso introduz:
Consistência Eventual
Ou seja:
Um produto pode ser salvo no MySQL e aparecer na busca alguns milissegundos depois.
Estratégias de Sincronização
Sincronização Direta
A API grava e indexa logo depois:
$productRepository->save($product);
$meili->index('products')->addDocuments([$product]);Simples, porém acoplado.
Mensageria
Usando:
- RabbitMQ
- Kafka
Fluxo:
Produto criado
↓
Evento publicado
↓
Consumer indexa no MeilisearchMais resiliente.
CDC (Change Data Capture)
Ferramentas monitoram mudanças no banco em tempo real:
- Debezium
- Maxwell
- Canal
Sincronização automática e desacoplada.
Resultado Final
A arquitetura se torna:
- elástica
- desacoplada
- resiliente
- escalável
Capaz de suportar milhões de buscas sem comprometer a saúde do banco transacional.